Tuesday, August 22, 2006
使用fontforge
字型: 文鼎 PL 標楷體(繁)
排列順序是依照 Unocode 的順序排的, 沒有字元的地方會出現 X

(1) A 96 pixel display showing the various vertical metric lines.
(2) 藍: vertical baseline, 紅: vertical origin, 綠: It shows where the vertical advance is while the green line on the right shows how long it is.(應該是指EM的大小吧...)
Wednesday, August 16, 2006
[目錄]Feature Extraction Methods
目前只看到 chapter 1
因為後面的演算法用了很多 "fourier transformation" 和 "線代"
要去複習才看得懂QQ...
《FEATURE EXTRACTION METHODS FOR CHARACTER RECOGNITION--A SURVEY》 (1995)
目錄
1. Introduction
1.1. lnvariants
1.2. Reconstructability
2. Features Extracted from Gray-scale Images
2.1. Template matching
2.2. Deformable templates
2.3. Unitary image transforms
2.4. Zoning
2.5. Geometric moment invariants
2.6. Zernike moments
3. Features Extracted from Binary Images
3.1. Template matching
3.2. Unitary image transforms
3.3. Projection histograms
3.4. Zoning
3.5. Geometric moment invariants
4. Features Extracted from the Binary Contour
4.1. Contour profiles
4.2. Zoning
4.3. Spline curve approximation
4.4. Elliptic Fourier descriptors
4.5. Other Fourier descriptors
4.6. Evaluation studies
5. Features Extracted from the Vector Presentation
5.1. Template matching
5.2. Deformable templates
5.3. Graph description
5.4. Discrete features
5.5. Zoning
5.6. Fourier descriptors
6. Neural Network Classifiers
7. Discussion
8. Summary
[內容整理] FEATURE EXTRACTION METHODS
Abstract
This paper presents an overview of feature extraction methods for off-line recognition of
segmented (isolated) characters.
Selection of a feature extraction method is probably the single most important factor in achieving high recognition performance in character recognition systems. Different feature extraction methods are designed for different representations of the characters, such as solid binary characters, character contours, skeletons (thinned characters) or gray-level subimages of each individual character.
The feature extraction methods are discussed in terms of invariance properties, reconstructability and expected distortions and variability of the characters. The problem of choosing the appropriate feature extraction method for a given application is also discussed. When a few promising feature extraction methods have been identified, they need to be evaluated experimentally to find the best method for the given application.
* Different feature types may need different types of classifiers.
* ["特徵截取"的定義] Devijver and Kittler define feature extraction [page 12 in reference (11)] as the problem of"extracting from the raw data the information which is most relevant for classification purposes, in the sense of minimizing the within-class pattern variability while enhancing the between-classs pattern variability".
(就像之前有篇paper說的, 選用的特徵值, 必須使同一個使用者的每個文字間的差異
達到最小, 但不同使用者的文字間要有明顯差異, 這樣才能區分不同的人寫的字)
* 一個好的 feature extraction method 對你將應用到的地方是很重要的.
* Also, more than one pattern class may be necessary to characterize characters
that can be written in two or more distinct ways. (要考慮到一個字元的不同寫法)
Tuesday, August 15, 2006
standard font list
文鼎私房字
談漢字電腦字型的寫法問題
(一)文字之形成,必經演化及約定俗成之過程
電腦字形之產生,乃是近代印刷科技發展的一個配合產物。它雖然是一種科技的表現,但漢字的表現上其所要呈現的內涵,還是東方漢文字的風華再現。
.....
中國文字的結構,由於是由許多筆劃之元件所組成,而其發展及演變,也跟著書寫字體之演變,整個約定俗成的過程有其發展之軌跡,但真正要寫成什麼樣子一切還是操縱在書寫者手中。
.....
同樣一個字,由於結構、筆勢、書風之差異,而致使其展現出之文字風貌或柔媚、或勁健;或刀劈斧砍、或溫柔婉約,各呈風騷不同。
.....
因此在印刷字型的開發上,定義每一個字碼的明確文字形狀,這是絕對必要的。所謂書同文,車同軌,這是文字使用上,必須先行建立的共通標準。又因為文字寫法 之形成有其演化的過程,是有其文化性,及習慣性的,因此其完整文字之呈現通常是非常主觀地感受地。因此在一套印刷文字的開發同時,其文字應用的目的一旦設 定,就要同時考慮既要滿足共通標準之需求,又要滿足讀者習慣領域、文化感受的需求。
(二)字形之正、異體字問題及筆法、寫法的問題
圖一~三分別代表古代書法作品、現代業界印刷用字型、現代教育用字型之不同風貌。
.....
要探討寫法的問題,首先我們要先釐清正、異體字的存在的問題。我們從古代書法作品中發現無論寫法或運筆其自由度相當之高,如《既》、《高》、《顙》、《頤》之寫法,與現代之用字之寫法是不同的,原因為何呢?
.....
其原因乃在於文字歷史演化下之產物,這些同義同音卻不同形的字形,其演繹都散見於我國歷代的典籍書冊中,我們不能無視於它們的存在,因為這些就是我們文化 的一部分。
.....
而我們在繁體中文電腦系統中因為系統的限制、效率之問題,有使用字數之限制。因此 所使用的Big5字集,其中所收錄的字形就必須取較為常用的字形,因而形成正字與異體字的雜混情形。如《頤》、《顊》,前者被收錄在Big5字集中之第一 字面(常用字面),後者被收錄在Big5字集中之第二字面(次常用、罕用字面),因為我們使用的Big5字集收錄的漢字僅有13,060字,但依教育部所 收錄的異體字集,則共有106,152字。這是因為Big5字集是針對我們日常較常使用的漢字收錄,因此必須針對商業上使用頻率多寡而做取捨。但教育部異 體字之收錄則希望能儘量收盡文獻、文化用字,因此有106,152字之龐大之數,而這麼大的字集,如何使用也是一大問題,我們將於下其中討論。
除 了文化用字族群外,尚有一般人民之姓名用字之大族群,這部份依據最新的更新資料,文鼎提供給健保局承保系統所使用的ATE-EUC大字庫系統中,所使用的 字就有73,973字之多,這比現有戶政單位所使用的字數還略多些。但以文鼎承做主計處的CNS標楷體12~15字面時所做的文字整理,發現其中的重複 字,竟有上萬字,也就是說這73, 973字其實至少還可刪掉上萬字。為什麼會發生這樣的事呢?除了人為因素外,還有些瓶頸待克服,我們接著說明。
大家可能想知道,結合《文化用字》、《戶政用字》其聯集字集到底有多少字?目前來說是:不知道!
因 為這工作還未經整理過。但在整理前有一件事要先做,那就是要定義《寫法的標準化》,這邊的寫法不是指著正體、異體的寫法,正體、異體之差異,在文字發展上 是可考據的,因此要釐清並不難(我們已就此點做過說明)。但這裡的《寫法的標準化》,指的是一點一捺的正確寫法,因此更貼切的來說,應該是《筆法、寫法的 標準化》。(見下表)

(三)應用上及形成的影響或是跨國際間漢字使用的狀況
在上期中我們談論了文字字形、寫法在實事求是的科學角度下,必須予以明確定義的必要性。
但若如教育部所定寫法、筆法規範,來設計所有的字體因為很難跳出這 個框架,所以很難適用於各種不同造型的字體,以符合市場各種不同的需求。因此,根據應用上的需要,通常會將寫法要求標準予以區分,就如發展較完整的日本來 說,就分為教育用字由文部科學省負責、產業用字則由通商產業省負責,而現今流通於市的平成明朝體,就是由此單位所規劃。
為避免使用字形紊 亂,大陸則是號令一致由《電子技術標準化研究所》訂定宋、仿、楷、黑四套外框字型標準、頒訂多種的點陣字國家標準,任何電子產品要內嵌字形,若要用到點陣 字,只能跟國家授權,不能跟廠商購買。
.....
而以國內來說,教育部曾開發多套標準字體書面母稿(宋、楷、黑、隷),希應用於國中小學教育用書中。但至今國內目前流通的電腦標準字體字型,也只有《文鼎標準楷書》取得教育部審核通過之認證書,其他標榜標準字體之廠商,並未能獲正式認證。
現 今,政府大力推動e-Taiwan之六年國建計畫,為能統一中文之使用。因此,若已被收內在國家標準CNS之用字,其寫法標準由教育部負責製作、審核;未收納的字,則由行政院主計處負責編碼、整理、製作。但這些都屬官方正式用字,沿用的都是教育部的標準宋体、楷體之寫法、筆法標 準。但產業上的用字並沒有哪一個單位負責或出來整合。以目前來說仍以Big5字集為主,一共有13,060個漢字,但其中每一碼位的定義,並沒有標準,因 此就顯得非常雜亂,尤其是符號區,更是各家不一,不能說哪一家對,哪一家錯,因為沒有標準!
下表,列舉了國內兩大字型廠商、視窗系統所內附多種基本字型之寫法。
我們以經過教育部認證過的《文鼎標準楷書》為基準,來做一些比較。

‧MS新細明《神》、《祈》其部首寫法竟不同。
‧大部分印刷字體(明、黑、圓)與書法字體(楷、隷)會有兩種不同系列的寫法設計。
‧標準字體因經過來源出處的考證,因此會與仿間流傳的寫法有些出入。
‧總體來看,因為漢字之複雜及字數繁多,因此每家廠商之字體寫法統合上,都可見到不是那麼完整。
我們知道要維持產品的完整,必要的寫法整合、一致性當然是必要的,但若過度的追求標準化,則印刷文字的文化性、藝術性、設計性,相對的就會降低。
.....
當我們的書寫習慣逐漸由手寫轉而使用電腦輸出時,以往豐富的個人特質書寫風格, 也會逐漸被制式的電腦字型所取代。因此在追求印刷字型這種工業藝術的更高產品品質時,我們也希望能找出一種能平衡工業與藝術的產品設計,文鼎希望能開創一 種字型產品,既能讓大家在電腦上方便使用,又極具藝術性、文化性,以作為當代印刷字型的精神之作。
.....
但同一種字體,所有的《的》都是一樣的,不能像手寫文稿般,文字能依上下文字而去作行氣的調整變化,這非關正確性, 而是一份承載情感的感性。
這是我認為身為當代印刷字體開發廠商應該去追求的工藝文化,因此我認為具教育性、政府公文書用字,應嚴格追求寫法、筆法之標準化;但在產業、文化用字之寫法、筆法上,則應在標準化、文化性上求取應有的平衡,以求能創作出具風格特色的當代印刷字體,以豐富我們的人文生活。
我們一再強調印刷字型的文化性,我們來看看在追求全球化趨勢下,在此的現狀為何?
我都知道在電腦字型編碼上,我們已逐漸採用全球通行的Unicode編碼,大家原本認為一套Unicode/CJK就可通用於亞洲漢字語系,這是大家認為全球化趨勢下的一個設計,我們來看看在實際面上會有的問題。
下圖(圖一)是我擷取自大陸所出版的國家標準13000.1-93一書中,將Unicode中放在同一碼位中各國之來源字都列示在一起,如《台》字,都依序存在於原簡体GB、繁體CNS11643、日文JIS、韓文KSC編碼中(編碼說明見圖二)。

圖一

圖二
我們來仔細探討其中各地區編碼寫法上的差異,請見下表幾個例字及說明。

每個地區都有不同的寫法或筆法,雖在定義上該碼位上的字都視為同一個字,但使用在不同地區時,就是要用該地區習慣的寫法,甚至還要 分是教育及政府用字或是一般產業用字,這是全球化理想下無法以一套字通行於天下所滿足的,若硬要統一,則各地區的文化特色便蕩然無存,無論哪一個地區的政 府或是一般使用者都無法認同的。
我們一連談了三期的印刷字形寫法的問題,我們從漢文字的發展談到標準化的問題,也從文化傳承談到全球化趨 勢的面臨問題,希望能對大家有所幫助。這些文字是無時無刻都跟我們的生活結合在一起的,不相信的話拿起你的手機試試裡面的用字,看它的寫法是依據什麼?就 知道廠商有沒有用心?
不過在文章最後我想提出一點給大家思索,我們教育部所設計的標準宋體造型,很不同於一般市場的明體或宋體造型(見上表例字),我們有機會的話好好探討一下。
編碼標準比較
大五碼 (Big-5)
大五碼是台灣各大中文軟件發展商十多年前訂立的編碼標準,包含約 13,000 個繁體中文字。
國家標準碼 (GB)
國家標準碼是中國政府的國家編碼標準。它的最新版本是於二零零零年公佈的 GB 18030-2000,包括約 27,000 個中文字符。
ISO 10646 國際編碼標準
ISO 10646 國際編碼標準是由國際標準化組織制訂的編碼標準,包含世界上主要語文的字符。其中的漢字部分,將中國、台灣、日本和韓國所訂立的漢字編碼標準統一,成為一個約有 70,000 個漢字的字集。ISO 10646 國際編碼標準可被視為與統一碼 (Unicode) 等同。
Sunday, August 13, 2006
Adobe Tecnical Notes 閱讀文件整理
Technical Note #5080 ---May 27, 2003
《Adobe-CNS1-4 Character Collection for CID-Keyed Fonts 》
(發展字型時需要的字元集)
以下摘自其Introduction:
This document is useful for font developers wishing to develop Chinese language fonts for use with PostScript ® products, and for software developers and end users wishing to access glyphs based on this character collection.
(此文件適用於使用Postscrip的產品以開發中文字型者、軟體開發者、及想取得字型中的 glyph 資料的使用者)
Technical Note #5092 ---Sep. 12, 1994
《CID-Keyed Font Technology Overview》
之前文章有提到
文鼎中楷
Saturday, August 12, 2006
上屆大四學長的程式
1. 用 VC++ compile 時沒反應, 然後再按 execute 會出現記憶錯誤, 按"確定"後整個VC++就關掉了

2. 用 DevC 跑沒反應
Windows API 入門
from: 天藍工作室
目的: 使用 Windows API 來繪製視窗
GDI (Graphics Device Interface) 函數專責處理程式介面和顯示卡的資料傳送,我們只需建立一個 device context handler (HDC) 就能使用 GDI 函數
* 在視窗程式中,每個物件都需有一個 handler 作為介面,這點要緊記。
Tuesday, August 08, 2006
Rearranged fonts

Sunday, August 06, 2006
tomorrow
1. http://edt1023.sayya.org/fontforge/overview.html 英文部分看完
2. 看貝茲曲線的資料
3. 印出一個中文字元的 glyph 的資料, 看它怎麼紀錄
4. 看懂學長程式中至少一個特徵的套用
5. TTF 文件的第一份再看一次...
jargon words
1. WEIGHT
Weight is strictly an indication of the amount of vertical thickness in the characters of a font.
The main weights on offer these days are Extra Light, Light, Book, Medium, Semi-bold, Bold, Extra Bold and Black.
2. KERNING
Kerning is the reducing of the space allocated to one or both sides of a letter to make it fit more comfortably with its neighbour, to improve the colour in a word.
字體空隙最佳化
3. TRACKING
should not be confused with kerning. Tracking is an overall increase or decrease in letter spacing over a line, or over more than a line, to make it fit better.
4. ligature
連字(兩個字母相連)
5. character vs. glyph
A character is an abstract notion denoting a class of shapes declared to have the same meaning or form. A glyph is a specific instance of a character.
(ex. character 指所有字型中的"a"的不同樣貌; 但各字型中的"a"各自稱為一個 glyph)

6. decision trees
7. pattern recognition 辨識模式, 影像識別
8. invariant moment 恆定矩量
9. moment (力)矩
10. Optical character recognition (OCR) 光學字元辨識
中文輸出字型
Chapter 5. 中文輸出字型
(1).點陣字(Bitmapped Fonts):
點陣字是早期開發之中文系統字型,同時也是一般螢幕顯示常用的字型,點陣大小主要分16x15或24x24二種字級。以24x24 字級為例,其造字原理是由每邊24點的正方形點陣來構成一個文字,其中每個點以亮或不亮的方式來組合一個字的外型。
因此以24x24 字級為例,每個字所佔的空間為24x24=576 bits=72bytes,完整的一套中文字型便需要24x24x13051=7517376 bits=939672 bytes,倚天中文的 STDFONT.24字形檔就是存放這種字型。早期字體放大的作法是將原本造字的字級,將點數往垂直或水平的方向增加來達成文字放大的效果。這種方法在文字斜線部份放大時便會出現十分明顯的鋸齒狀變形,為了改進這個缺失,造字廠商便以推出更高字級字形的方法來因應,如32x32、48x48‥‥等字級來替代原本直接以低字級放大的處理方法。
這種方式雖然字體美觀的要求滿足了,但是字形所需的硬碟空間卻相對膨脹,例如48x48 字級每個字即需要48x48=2304 bit的空間,同理,一套完整的字體就要約4MB 的空間,更高字級所需的空間更是以幾何級數的倍數激增。為了改善點陣字的這些弊端,向量字應運而生。
代表字型 BDF(Bitmap Distribution Format,點陣分散格式)、HBF(Hanzi Bitmap Font,漢字點陣字體)、PCF(Portable Compiled Font)
(2).向量字
向量字是以許多的線段來組成文字的外型,因此在文字放大時只要改變每個線段的長度就可以無限制地在字體的大小上做變化,不需要多套不同字級的字體,也不會產生鋸齒狀,同時文字所佔的空間也相對減小。
唯中文字並不是全由線段構成,在以線段來表示曲線的部份尚不能達成完全的平滑要求,當文字做高倍率的放大時,一樣會在曲線部份出現折線;如果以更多的線段來表示曲線,雖然可以將曲線部份描繪地更圓滑,但字體所佔的空間也是相對地增加,所以並非治本之道。為了提高文字顯示的品質與效率,曲線字繼之而起,這也是當前WINDOWS下中文的主流。
(3). 曲線描邊字(outline font)
曲線描邊字是由幾個點來組成曲線,再由許多曲線來勾勒出文字的外型。要放大或縮小文字,只要調整這些控制點的位置即可完成,並且透過控制這些曲線點的方式,還可以做到平移、旋轉或改變文字的外型,因此曲線字不但文字美觀,空間小,同時更富有變化。
不過曲線字與向量字都需將曲線與文字的資料加以運算轉換,經組合後才能得到字型的資料,因此文字呈現的速度較為緩慢。Windows 系統下的標準字型TrueType(在 Windows中這種字型前面都印有二個重疊的T字) 字型即是一種以BSprine曲線來描邊的字型,TrueType字體免除了向量字體的一些缺點,它可以自由定義各種尺寸的字體,而且不失真,不管是螢幕或是印表機都使用同一種字體,讓使用者在螢幕上所看到的和印表機輸出的完全相同。
5.1. 字型格式
5.1.1 PostScript
於Aug. 2, 2006 中有文章介紹囉.
5.1.2 TrueType
TrueType字型格式為美國 Apple 及Microsoft 所共同制定,最先使用於Apple的Macintosh系列及 Microsoft Windows 3.1, 而目前Apple的OS 8.0及 Microsoft Windows 95/NT/2000/XP也都使用 TrueType作為字型格式。
基本上TrueType和PostScript一樣,都是使用貝茲曲線(Bezier Curve) 來描述的外框字。 其字型可以作任意尺寸的放大縮小, 或作其他屬性的變化,不過由於Apple及Microsoft 的作業系統都直接支援此字型格式,所以並不需要如PostScript 一樣,外掛(Adobe)Type Manager之類的程式。
手寫體和印刷體
1. 就字"形"來看, 可發現, 有的"型"偏向人們書寫方式; 有的則是印刷用的, 一般不那樣寫.
2. 同一個字, 但卻有不同的形, 在 Unicode 中各"形"有不同的編碼.
3. 目前先取教育部標準字形來做"標準字型"的參考.
=================================================================
1.摩托學園討論區中的[各字型的比較]
不是只有英文有分手寫和書寫體喔, 中文也有:
其分析如下:
傳統的印刷字體:『微軟細明體』、『cwTeX 明體』、『王漢宗細明體』
手寫體:『(新)微軟細明體』、『華康標準宋體』、『文鼎 CS 報宋』、『文鼎 CS 書宋』
中間派:『文鼎 (Firefly) 新宋體』,有些是傳統的印刷字體,有些則是比較接近手寫體。
2. 李果正先生的 Font Note
就以和英文羅馬字族相當的明、宋體來看:
明體可以視為印刷體,利於印刷閱讀,兼具美觀。而宋體就比較接近我們的書寫形式,我們來看看他們的不同點:

哈,和英文的情況還真類似,到底是誰學誰?這大概是人類自然的本能所引致的吧!所謂,「英雄所見略同」!
但現在問題來了,Unicode 協會 把他們分別編上了不同的編碼,雖然也有說明是同一個字,但編碼不一樣,在字型製作及電腦軟體的應用上就大不相同。例如,我們慣用的明宋體字型的區分將會被打破,長期而言會影響一國的文字文化。
像這種字的形狀不同,但卻是同一個字的情形,除非是異體字的情況,不然似不應分成不同的編碼較妥。我們可以由字型的製作及取用上去做區分,否則英文手寫體的字母,是不是也得另外編上不同的編碼呢?另外,中文的草書體,是否也得另外編上不同的編碼?
serif 及 sans serif
整理自 [果正札記]
在西方國家的字母體系,分成兩大字族:serif 及 sans serif 。其中 typewriter 打字機字體,雖然也是 sans serif,但由於他是等距字,所以另獨立出一個 Typewriter 字族出來。
serif 的意思是:在字的筆畫開始及結束的地方有額外的裝飾,而且筆畫的粗細會因直橫的不同而有不同。相反的,sans serif 就沒有這些額外裝飾,而且筆畫粗細大致上是差不多。

serif 的字體→ Times、Times New Roman 等;sans serif 的字體→ Arial、helvetica 等。
serif 和 sans serif 的一般比較- serif 的字體較易辨識,也因此易讀性較高。
- 反之sans serif 則較醒目,但在走文閱讀的情況下,sans serif 容易造成字母辨識的困擾,常會有來回重讀及上下行錯亂的情形。
- serif 強調了字母筆畫的開始及結束,因此較易前後連續性的辨識。
- serif 強調一個 word,而非單一的字母,反之sans serif 則較強調個別字母。
- 在很小字的場合,通常 sans serif會較 serif 字體較為清晰。
適用於不同用途
通常文章的內文、正文使用的是易讀性較佳的 serif 字體,這可增加易讀性,而且長時間閱讀下因為會以 word 為單位來閱讀,較不容易疲倦。而標題、表格內用字則採用較醒目的 sans serif 字體,他需要顯著、醒目,但不必長時間盯著這些字來閱讀。
像 DM、海報類,為求醒目,他的短篇的段落也會採用 sans serif字體。但在書籍、報章雜誌,正文有相當篇幅的情形下,應採用 serif 字體來減輕讀者閱讀上的負擔。
中文的情況
在中文的情形也是有相當於 serif 的字體,例如:
- 明(宋)體就是serif 的,他通常是和 Times Roman 字族來搭配的。
- 而黑體、圓體就相當於是 sans serif 的字體。
在中文直排的情況,比較不容易顯現 serif/sans serif 之間的差異性,但是在目前中文橫排相當的普遍的情形下,以上所述及的易讀性、醒目性也是適用於中文。


很常看到中文出版書籍、雜誌,內文使用了不易閱讀,但卻很醒目的黑體或圓體,這對讀者來說,在長期閱讀之下很容易就引起眼睛不舒服,似乎是應該盡量避免才是。
Saturday, August 05, 2006
CID-Keyed font
===================================================================
from: Adobe《Adobe CMap and CIDFont Files Specification》---June 11, 1993
A CID-keyed font is a font program that maps character codes to CIDs, and uses CIDs to access glyph data.(下圖為清楚的示意圖)
character code →[CMap resource]→CID→[CID Font resource]→glyph data
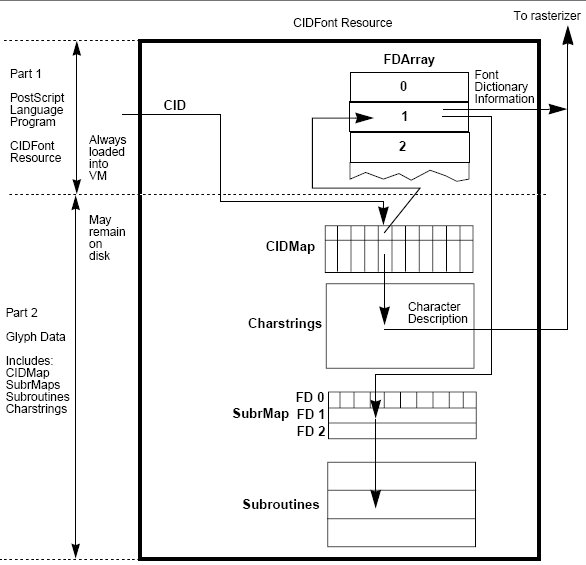
(下圖)Figure 2 is a data flow diagram of the internal organization of a CIDFont.
In VM, the CMap resource produces a character ID for use by the CIDFont resource. The character ID acts as an index into the CIDMap, which is in turn used to locate other pieces of information. Each interval of the CIDMap also has two parts: (1) an index into the
FDArray, which is an array of font dictionaries. (2) an offset into the charstring data. Charstring data, subroutine information (if any), and data from the appropriate member of the FDArray of font dictionaries, are required to rasterize a glyph.
===================================================================
from: Adobe Tecnique Notes #5092 ---Sep. 12, 1994
用來理解TTF檔中 cmap 表的使用方式, 以及 Font developer 如何使用 CID 來發展新字型
* Abstrasct
同一個字元不同的編碼方式(Big5, Unicode...)下, 會有不同的 encoding id, 而我們將任一語言的常用字元編成一個 character collection, 並給每個字元一個 id (即CID), 如此一來, 不同編碼下的同一字元即可對應至相同 CID , 使開發新字型更為方便.
* Character ID (CID) numbers is are used to index and access the characters in the font. They are based on a predefined and named character collection, and a specific ordering of that collection.

- New Counter Control Hints
One type of hint information that is paticularly important for complex CJK characters is the
Counter Control hint ( counters are the white spaces between stems in a character). It helps insure that counters and overall proportions are rendered as accurately as possible, subject to the number of pixels available for a given size and resolution. (幫助字元在任何大小和解悉度的環境中都能儘量以正常地"形"顯示出來)

* CID-Keyed Font Components
one or more CMap files and a CIDFont file.
- Character collection
A character collection consists of an ordered set of all characters needed to support one or more popular character sets for a particular language. The order of the characters in the Character Collection determines the CID number for each character.
Adobe Systems publishes character collections for Chinese, Japanese, and Korean fonts; 字型發展者即可利用這些現成的 character collection 來發展其字型
- CMap files
CMap (Character Map) files specify the correspondence between a character code and the CID number used to access the character description in the CIDFont file.
- CIDFont Files (字型開發者要做的就是這個囉~)
The CIDFont file contains the characters in the font, each of which is a computer language procedure that “draws” a given character shape for either display on the screen or for printing. The CIDFont file is the only component that most font developers will have to produce.
The CIDFont file also contains tables that help the interpreter locate the required characters and associated data, as well as additional information called hints which help the interpreter to create high-quality images of the characters at small sizes or at low resolutions.

===================================================================
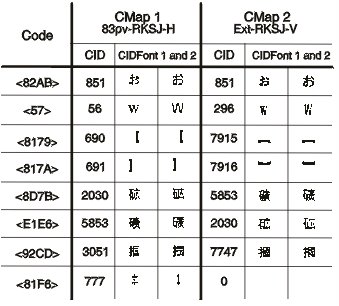
* from IBM
Figure 2. One CMap and two CIDFonts or two CMaps and one CIDFont. This figure was created by Adobe Systems, Inc.
Wednesday, August 02, 2006
Hinting
CharacterSet。Encoding
from: Adobe Tecnique Note #5080
A character collection contains all glyphs required to make fonts for a particular language or market. Encodings are specified by CMap (Character Map) files, which generally reference a subset of the character collection. Each CID (Character ID) is associated with a class
of glyph shapes.(這句我不懂) The specific shape of a glyph from a given class is dependent on the typeface style, the language, orientation, and writing direction of the font, and possibly other factors.
(字型開發者可能使用此 character collection 中的的部分文字來發展其字型, 此時就需要使用CMap 來為字元做對應。其中, 每個 CID 跟 glyph 的外型有關。)
===================================================================
中文字在目前常見的電腦上是由兩個位元組(two bytes) 所編碼組成的。最常見的編碼方式有台灣地區所通行的 Big5 編碼,及大陸地區所使用的 GB 編碼。而且開頭的位元組幾乎都是大於 128 的數值,也就是所謂 non-ASCII 碼的範圍(ASCII 是指小於 128 的編碼)。
字集(Character Set)是一組符號或文字的組合,而編碼(Encoding)則是將這一組符號或文字以適當的方式編入位元組中, 以便電腦能夠表示與儲存。目前現有的字集如中文字集、英文字集、日文字集等,而中文編碼則是選取部份或全部字集中的部分或全部字, 給予一個號碼,如 Big5 包含部分中文字集、英文字集、部分日文字集等。
接下來就是萬碼奔騰,眾多中文編碼標準的問題,目前台灣使用的中文編碼存在許多問題,第一是中文編碼有數種 Big5、CCCII、CNS11643、Big5E、Big5+、ISO 10646、CP950、EUC-TW,每個編碼所包含的中文字數不同,編碼方式也不相同, 而且大部分都沒有國家標準規格,第二是常用的 Big5 編碼字數不足。
雖然常用的 Big5 已經使用 2bytes 來表示中文字,但是 2bytes = 16bits = 2^16 =65536 個編碼空間, 以 Big5 的標準而言,為了要和 ASCII 能夠相容,最多只能使用兩萬多字 ([0x80-0xFE][0x40-0x7E,0xA1-0xFE] = 127*190 = 24,130),現存的中文字最少在七萬以上,造成許多字在 Big5 的系統下,無法使用。在加上中文標準繁多,卻又沒有最後的國家標準規格,各家廠商所實做產品也就未必相容。 最明顯的例子就是日文平假片假名,在這些中文編碼中並不是每個都包含, 當遇到所謂的「Big5日文」時,就會產生許多問題。
===================================================================
PostScript 概論
PostScript為美國Adobe( http://www.adobe.com)公司於1985年所發表的文件描述技術,Adobe並利用這個技術,創造著名合乎PostScript技術的字型,並從而改變整個印刷工業,PostScript 可以精確的描述平面繪製任何文字及圖形,現今PostScript 的技術已經非常普遍的使用在印刷領域,包括螢幕顯示(Display), 雷射印表機(Laser Printer),輸出機(Imagesetter), 數位印刷機(Digital Printing)..等等輸出設備。
而與PostScript技術搭配最重要的是PostScript字型,使用者可以透過PostScript技術調整某些參數,而改變字型的大小,陰影/立體/空心/粗細等特殊效果, 由於PostScript在印刷方面卓越表現,目前世界上主要的文獻幾乎多是以PostScript的形式出現。
目前常見的中文列印方案都是產生 Postscript 後,再進行列印。產生的檔案又可分為內嵌(bg5ps、enscript、cnprint) 與不內嵌字型(truetype、cid font),目前的解決方案偏向於使用 CID-Keyed font。
CID-Keyed font,CID是Character ID的簡稱。
CID字形格式的設計主要是為了各種PostScript輸出設備, ATM(Adobe Type Manager)軟體, CPSI(Configurable PostScript Interpreter)解譯器及 DPS(Display PostScript)顯示型PostScript軟體等, 能使用於大字庫字體集,特別是台灣、大陸、日本、韓國等雙位元語系的國家文字。
CJK(Chinese , Japan , Korean)字集上日、韓二國文字,除了平假名、片假名及韓文字外,佔最多字體容量的還是漢字部份,而且中、日、韓的漢字很多都是相同的漢字,如果一套CJK字集能包括 Big5、GB、JIS及KSC碼的所有的字形、容量一定比四種碼位分開的字形少30%以上,而且可以不用擔心,以後從以上四個地區來的文件,輸出時沒有對應的字形輸出。
在1990年Adobe發表可以支援雙位元架構的PostScript字形格式, 一般通稱為OCF(Original Composite Font)格式, 它使用比較複雜字形構造及字形儲存方式,因為它為了要支援雙位元的字形,就必須要做成這樣複雜的架構,像目前大家所使用的中文Type1、Type3、Type4等字形格式, 都是屬於OCF格式。
OCF字形要抓取列印一個雙位元字形時,必須要經過複雜的對應關係,才能取得字形的外框資料去列印,所以Type1、Type3、Type4等OCF 字形的檔頭(header)描述都非常複雜, 而且每一家字形廠商都不太一樣。
CID字形的架構比OCF字形就簡單多了, 直接由CMap檔案去對應字形外框資料,所以解譯器能快速的取得及解譯字形的外框資料及列印, 而且比較節省記憶體的使用。
Character Collection(字形集)及CMap File(對應檔)這二者Adobe 有定義標準格式,字形廠商可以使用Adobe的標準格式,以繁體中文為例,Adobe定義一個Character Collection,和很多個的CMap File,如Adobe-CNS1-0,B5-H,B5pc-H,ETen-B5-H 等不同的CMapfile。 不同的CMap file使用於不同的內碼系統,如果這些內碼系統的字碼有擴充時,只要增加新的CMap file及CID 字形即可,可以不影響到原來的CMap file及CID字形檔。
today's note
1. ttf中, 順時針方向的點會圍成實心, 逆時針方向則圍成反白區
2.曲線描邊字型(Outline Fonts)
- PostScript (Adobe)
- TrueType (Microsoft, Apple, Adobe )
- OpenType (Microsoft & Adobe 合作開發):
內容主要包括 TrueType 或 Type 1 資料的壓縮, 然後增加延伸功能, 如連筆功能等,資料結構上和 TrueType 差不多, 使用 Tables 來紀錄字型資訊
3. TrueType 字型發展:
TrueType → TrueType Open → OpenType (三者基本的 container 格式相同)
4. 中文字的顯示 (自己寫的...)
(1) 中文字編碼:Unicode, UTF-8, Big5, ....
(2) 中文字型:由"每個字元唯一的編碼"對應到"字元外框資料", 然後畫出來(rasterize)
(3) 輸入法:目前還不了解如何對應